[last updated 2025-10-13]
Overview
GDAL implements read/write memory caching for raster I/O. Caching
operates on raster blocks and offers potential for substantial
performance improvement when accessing pixel data across block
boundaries. In an analytical context where processing may be
row-oriented, this means that I/O can be efficient even when rows
intersect many tiles of a raster arranged in square blocks (as opposed
to blocks arranged as one whole row). Consideration of the caching
mechanism is helpful for scaling I/O to large datasets that need to be
processed in many chunks. This article will describe the operation of
the caching mechanism, and relative performance when accessing data by
row or by tile in relation to different raster block arrangements.
Implications for configuring cache memory size with the
GDAL_CACHEMAX setting will be described. Focus here is on
reading pixel data, but similar concepts apply to writing as well.
Relative performance
A dataset containing 16-bit integer elevation at 30-m pixel
resolution for the conterminous US was obtained from LANDFIRE. The version is “LF 2020
[LF 2.2.0]” which is available as an 8.4 GB download. The download
includes raster overviews (as .ovr), but the elevation raster itself is
a 6.8 GB GeoTIFF file using LZW compression on 128 x 128 tiles. The
direct download link for LF 2020 elevation is:
https://landfire.gov/bulk/downloadfile.php?FNAME=US_Topo_2020-LF2020_Elev_220_CONUS.zip&TYPE=landfire
Tests were run on a laptop with Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz, 8 GB RAM, Ubuntu 24.04.3, R 4.3.0, gdalraster 2.2.1.9040 (dev), GDAL 3.11.3.
Open the elevation dataset and get parameters:
library(gdalraster)
f <- "LC20_Elev_220.tif"
ds <- new(GDALRaster, f)
ncols <- ds$getRasterXSize()
nrows <- ds$getRasterYSize()
paste("Size is", ncols, "x", nrows) # 1.587394e+10 pixels
#> [1] "Size is 156335 x 101538"
ds$getMetadata(band = 0, domain = "IMAGE_STRUCTURE")
#> [1] "COMPRESSION=LZW" "INTERLEAVE=BAND"
ds$getBlockSize(band = 1)
#> [1] 128 128
ds$getDataTypeName(band = 1)
#> [1] "Int16"The first test reads all pixels in the raster by row (using
GDALRasterIO() internally). For a tile size of 128 x 128
pixels, each row intersects 1222 raster blocks (156335 / 128 = 1221.4,
the last block is incomplete). This test reflects performance
implications of GDAL read-ahead caching:
## Test 1
## original tiled raster, reading by row (across block boundaries)
system.time(
for (row in seq_len(nrows - 1)) {
r <- ds$read(band = 1, xoff = 0, yoff = row, xsize = ncols, ysize = 1,
out_xsize = ncols, out_ysize = 1)
# process pixels, possibly write output...
}
)
#> user system elapsed
#> 120.641 3.515 127.562For comparison, we will read the same data from a raster arranged
with blocks as whole rows (efficient for row-level access).
gdalraster::createCopy() copies a raster dataset with
optional changes to the format. The extent, number of bands, data type,
projection, and geotransform are all copied from the source raster:
f2 <- "LC20_Elev_220_striped.tif"
opt <- c("COMPRESS=LZW", "TILED=NO", "BLOCKYSIZE=1", "BIGTIFF=YES")
createCopy(format = "GTiff", dst_filename = f2, src_filename = f, options = opt)
#> 0...10...20...30...40...50...60...70...80...90...100 - done.
ds2 <- new(GDALRaster, f2)
ds2$getBlockSize(band = 1)
#> [1] 156335 1
(ncols <- ds2$getRasterXSize())
#> [1] 156335
(nrows <- ds2$getRasterYSize())
#> [1] 101538This creates a “striped” tif with raster blocks arranged for
row-level access (TILED=NO is the default creation option
for the GTiff
format driver). The resulting file is larger at 10.6 GB vs. 6.8 GB,
since compression is less efficient for strips vs. tiles.
## Test 2
## striped tif, reading on block boundaries (rows)
## cache retrieval not involved
system.time(
for (row in seq_len(nrows - 1)) {
r <- ds2$read(band = 1, xoff = 0, yoff = row, xsize = ncols, ysize = 1,
out_xsize = ncols, out_ysize = 1)
# ...
}
)
#> user system elapsed
#> 118.075 4.642 123.441The next test reads by block on the original raster as distributed by LANDFIRE. To read by block on the tiled format we need to calculate the row/column offsets and x/y sizes for each tile, including the incomplete tiles along the right and bottom edges.
blocks <- ds$get_block_indexing(band = 1)
nrow(blocks)
#> [1] 970268
head(blocks)
#> xblockoff yblockoff xoff yoff xsize ysize xmin xmax ymin
#> [1,] 0 0 0 0 128 128 -2362395 -2358555 3263565
#> [2,] 1 0 128 0 128 128 -2358555 -2354715 3263565
#> [3,] 2 0 256 0 128 128 -2354715 -2350875 3263565
#> [4,] 3 0 384 0 128 128 -2350875 -2347035 3263565
#> [5,] 4 0 512 0 128 128 -2347035 -2343195 3263565
#> [6,] 5 0 640 0 128 128 -2343195 -2339355 3263565
#> ymax
#> [1,] 3267405
#> [2,] 3267405
#> [3,] 3267405
#> [4,] 3267405
#> [5,] 3267405
#> [6,] 3267405
tail(blocks)
#> xblockoff yblockoff xoff yoff xsize ysize xmin xmax ymin
#> [970263,] 1216 793 155648 101504 128 34 2307045 2310885 221265
#> [970264,] 1217 793 155776 101504 128 34 2310885 2314725 221265
#> [970265,] 1218 793 155904 101504 128 34 2314725 2318565 221265
#> [970266,] 1219 793 156032 101504 128 34 2318565 2322405 221265
#> [970267,] 1220 793 156160 101504 128 34 2322405 2326245 221265
#> [970268,] 1221 793 156288 101504 47 34 2326245 2327655 221265
#> ymax
#> [970263,] 222285
#> [970264,] 222285
#> [970265,] 222285
#> [970266,] 222285
#> [970267,] 222285
#> [970268,] 222285In terms of expected efficiency, reading the tiled raster by block is
similar to reading the striped raster by row (reading on block
boundaries, no retrieval from cache). The difference is that the striped
tif contains fewer but larger blocks (101538 blocks, 156335 pixels per
block), while the tiled tif contains order of magnitude more blocks that
are each smaller (970268 blocks, 16384 pixels per block). The following
test reads all pixels by tile from the original LANDFIRE elevation file
(LC20_Elev_220.tif):
## Test 3
## original tiled raster, reading on block boundaries (i.e., internal tiles)
## cache retrieval not involved
system.time(
for (i in seq_len(nrow(blocks))) {
r <- ds$readChunk(band = 1, blocks[i, ])
# ...
}
)
#> user system elapsed
#> 118.328 3.519 124.706To read on block boundaries but reduce the number of I/O operations
required to iterate the whole raster, larger chunks comprised of
multiple consecutive blocks could be defined. This may be more efficient
in some cases. Class GDALRaster provides a helper method
make_chunk_index() to compute the row/column offsets and
pixels sizes for multi-block chunks containing <=
max_pixels:
block_size <- ds$getBlockSize(band = 1) # block xsize, ysize
(max_pixels <- block_size[1] * block_size[2] * 32)
#> [1] 524288
chunks <- ds$make_chunk_index(band = 1, max_pixels)
nrow(chunks)
#> [1] 30966
head(chunks)
#> xchunkoff ychunkoff xoff yoff xsize ysize xmin xmax ymin
#> [1,] 0 0 0 0 4096 128 -2362395 -2239515 3263565
#> [2,] 1 0 4096 0 4096 128 -2239515 -2116635 3263565
#> [3,] 2 0 8192 0 4096 128 -2116635 -1993755 3263565
#> [4,] 3 0 12288 0 4096 128 -1993755 -1870875 3263565
#> [5,] 4 0 16384 0 4096 128 -1870875 -1747995 3263565
#> [6,] 5 0 20480 0 4096 128 -1747995 -1625115 3263565
#> ymax
#> [1,] 3267405
#> [2,] 3267405
#> [3,] 3267405
#> [4,] 3267405
#> [5,] 3267405
#> [6,] 3267405
tail(chunks)
#> xchunkoff ychunkoff xoff yoff xsize ysize xmin xmax ymin
#> [30961,] 33 793 135168 101504 4096 34 1692645 1815525 221265
#> [30962,] 34 793 139264 101504 4096 34 1815525 1938405 221265
#> [30963,] 35 793 143360 101504 4096 34 1938405 2061285 221265
#> [30964,] 36 793 147456 101504 4096 34 2061285 2184165 221265
#> [30965,] 37 793 151552 101504 4096 34 2184165 2307045 221265
#> [30966,] 38 793 155648 101504 687 34 2307045 2327655 221265
#> ymax
#> [30961,] 222285
#> [30962,] 222285
#> [30963,] 222285
#> [30964,] 222285
#> [30965,] 222285
#> [30966,] 222285
## Test 4
## original tiled raster, read in chunks defined as 32 consecutive blocks
system.time(
for (i in seq_len(nrow(chunks))) {
r <- ds$readChunk(band = 1, chunks[i, ])
# ...
}
)
#> user system elapsed
#> 104.987 4.319 112.861
ds$close()
ds2$close()Description of cache operation
GDAL block caching enables reading a large tiled raster by row efficiently (1.6e+10 total pixels in the test dataset). The default size limit of the memory cache is 5% of usable physical RAM. Each row of the LANDFIRE tiled raster intersects 1222 blocks of size 128 x 128. Each intersected block is read from file, decoded from LZW compression, and placed in cache memory. The data for each successive read request that intersects the same block are retrieved from cache. Caching all of the intersected blocks requires 128 x 128 x 2 bytes = 32768 bytes per block, 32768 x 1222 = 40042496 bytes, approximately 40 MB. All of the decoded block data for a row can be held in cache in this case, meaning that only 1 out of every 128 row-level read request involves retrieval from disk and decoding of compressed blocks. The other 127/128 are provided from cache. Memory is recovered when a request for a new cache block would put cache memory use over the established limit (least recently used blocks are flushed from cache to accommodate adding new blocks).
The code below uses the function
gdalraster::get_cache_used() to demonstrate the
behavior:
## run in a new R session
library(gdalraster)
f <- "LC20_Elev_220.tif"
ds <- new(GDALRaster, f)
ncols <- ds$getRasterXSize()
nrows <- ds$getRasterYSize()
## default cache size is approximately 400 MB in this case (5% of 8 GB RAM)
## read enough data to reach GDAL_CACHEMAX
rows_read <- 0
cache_use <- get_cache_used()
for (row in 0:1536) {
rowdata <- ds$read(1, 0, row, ncols, 1, ncols, 1)
rows_read <- c(rows_read, row + 1)
cache_use <- c(cache_use, get_cache_used())
}
get_cache_used()
#> [1] 401
ds$close()
get_cache_used()
#> [1] 0
plot(rows_read, cache_use, type = "S",
xlab = "rows read", ylab = "cache in use (MB)",
col = "blue", lwd = 2, xaxt = "n")
axis(1, at = seq(0, 1536, by = 128), las = 2)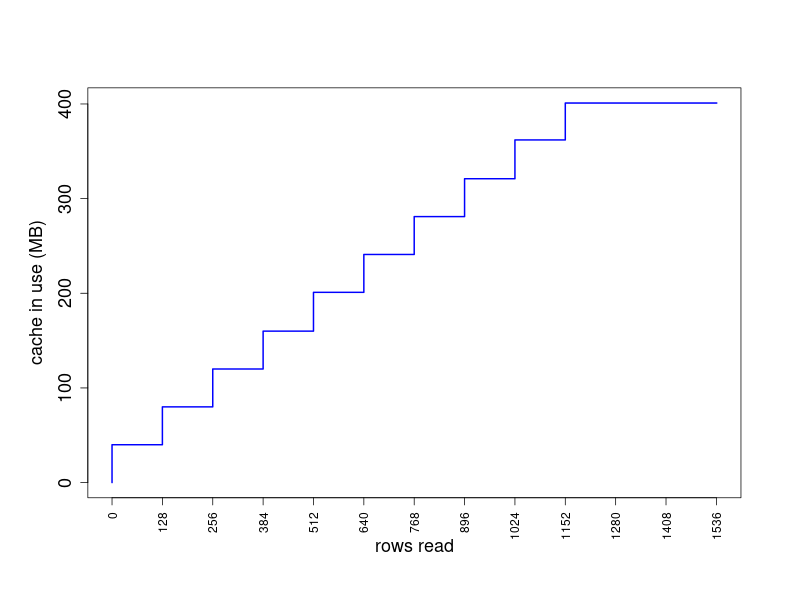
Configuring cache size
The cache size limit can be set with the GDAL_CACHEMAX
configuration option, e.g.,
## set to a specific size in MB
gdalraster::set_config_option("GDAL_CACHEMAX", "1000")
## or percent of physical RAM
gdalraster::set_config_option("GDAL_CACHEMAX", "20%")Note that the size limit of the block cache is set upon first use
(first I/O). Setting the GDAL_CACHEMAX configuration option
after that point will not resize the cache. It is a per-session setting.
If GDAL_CACHEMAX has not been configured upon first use of
the cache, then the default cache size will be in effect for the current
session. The value can be changed programmatically during a session
using the function gdalraster::set_cache_max().
I/O that involves block caching with large datasets may require
setting GDAL_CACHEMAX larger than the default. If the
LANDFIRE elevation raster were tiled at 256 x 256, then each block would
require 65536 x 2 = 131072 bytes for 16-bit data. The cache size needed
to hold all intersected blocks for a row would be approximately 160 MB
(and likewise, 640 MB for 512 x 512 tiles). Similarly, the cache size
could be configured for the case of multiple large rasters that need to
be read or written simultaneously for processing.
The cache is flushed upon dataset closing to recover memory. The
behavior described above assumes that the GDAL dataset is opened once,
and required I/O completed before closing the dataset. This would
normally be the case when using the GDAL API via gdalraster
(GDALRaster-class encapsulates a GDALDataset
object and its associated GDALRasterBand objects in the
underlying API).
It is also worth noting that without the block caching mechanism, it is not possible to read the tiled elevation raster by row in reasonable time. This can be checked by repeating Test 1 above with the cache disabled:
## original tiled raster, reading by row (across block boundaries)
## cache disabled for testing
## run in a new R session
library(gdalraster)
## for testing only
set_config_option("GDAL_CACHEMAX", "0")
f <- "LC20_Elev_220.tif"
ds <- new(GDALRaster, f)
ncols <- ds$getRasterXSize()
nrows <- ds$getRasterYSize()
system.time(
for (row in seq_len(nrows - 1)) {
r <- ds$read(band = 1, xoff = 0, yoff = row, xsize = ncols, ysize = 1,
out_xsize = ncols, out_ysize = 1)
# ...
}
)
system.time(lapply(0:(nrows-1), process_row))
#> ^C
#> Timing stopped at: 3650 42.97 3694 # killed with ctrl-c
ds$close()